
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
Tags
- 자바 개념
- Reversing
- 오라클DB
- 파이썬 알고리즘
- 러스트 프로그래밍 공식 가이드
- 오라클
- 운영체제
- 파이썬 챌린지
- 러스트 예제
- 데이터베이스
- 러스트
- data communication
- java
- 자바
- 알고리즘
- OS
- 백준
- 파이썬
- ubuntu
- Operating System
- 백준 러스트
- 파이썬 첼린지
- Python
- 자바 기초
- C
- Rust
- 데이터 통신
- Database
- Python challenge
- 우분투
Archives
- Today
- Total
IT’s Portfolio
[Python] 파이썬 웹 크롤링으로 지역별 코로나19 뉴스 정보를 크롤링해보자 본문
728x90
반응형
지금까지 쳐놀고 다른 일 좀 하느라 글 업데이트가 뜸했음 ㅋㅋ
오늘은 네이버 뉴스에서 지역별 코로나19 뉴스를 크롤링해오는 프로그램을 제작해보자.
준비물 : 신승훈의 I believe를 들으면서 하도록 하자. 개띵곡임 ㅇㅇ;;
import
import sys
from bs4 import BeautifulSoup
from datetime import datetime
import requests
import pandas as pd오류가 나면 프로그램 종료를 위한 sys
bs4와 requests는 크롤링 국룰
엑셀파일 제작을 위한 datetime과 pandas
coding
location_text = ""
title_text=[]
link_text=[]
time_text=[]
press_text=[]
result={}
RESULT_PATH ='C:/News Execl/'
now = datetime.now()지역 이름을 저장할 location_text와 뉴스 제목, 링크, 시간, 언론사 정보를 저장할 배열.
배열을 저장할 Dict까지
엑셀 파일이 저장될 경로와 현재 시각을 now에 저장.
def main():
location = input("지역을 입력하세요.\n>>> ")
finallocation = location + "+코로나"
crawler(finallocation)main 함수 정의.
지역을 입력 후 finallocation에 지역 이름과 코로나를 결합한 후 crawler 함수에 보냄.
def crawler(finallocation):
url = 'https://search.naver.com/search.naver?query=' + finallocation + '&where=news&ie=utf8&sm=nws_hty'
hdr = {'User-Agent': ('mozilla/5.0 (windows nt 10.0; win64; x64) applewebkit/537.36 (khtml, like gecko) chrome/78.0.3904.70 safari/537.36')}
req = requests.get(url, headers=hdr)
html = req.text
soup = BeautifulSoup(html, 'html.parser')
ErrorCheck = soup.find('div', {'id' : 'notfound'})
if not 'None' in str(ErrorCheck):
print("Error! 지역 검색 오류! 정확한 지역 이름을 입력하십시오.")
sys.exit(1)
else:
# 지역 뉴스검색 결과 텍스트
for i in soup.select('h1[class=blind]'):
LocationInfo = i.text
location_text = LocationInfo
# 뉴스 체크
checknews = soup.find('ul', 'type01')
print("* " + LocationInfo + " *\n=============================")
# 뉴스
for i in range(0, 100):
# 뉴스 타이틀 출력을 위한 체크 단계
firstnews1 = checknews.find('li', {'id' : 'sp_nws{}'.format(i)})
# sp_nws의 숫자가 일정하지 않기 때문에 걸러주는 단계
if str(firstnews1) == "None":
continue
firstnews2 = firstnews1.dl.dt.a
firstnewsinfo1 = firstnews1.dl.dd
# 에러 체크 단계
if str(firstnews2) == "None" or str(firstnewsinfo1) == "None":
print("Error! 개발자에게 문의하십시오.")
sys.exit(1)
else:
# 타이틀 및 하이퍼링크 추출
firstnews = firstnews2.get('title')
title_text.append(firstnews)
firstnewshref = firstnews2.get('href')
link_text.append(firstnewshref)
firstnewsinfo2 = firstnewsinfo1.text
# 신문사 및 기사 시간 추출
if "언론사 선정" in firstnewsinfo2:
firstnewsinfo3 = firstnewsinfo2.split("언론사 선정")
firstnewsinfo = firstnewsinfo3[0]
press_text.append(firstnewsinfo)
firstnewsinfo4 = firstnewsinfo3[1].split(" ")
firstnewstime = firstnewsinfo4[1]
time_text.append(firstnewstime)
else:
firstnewsinfo3 = firstnewsinfo2.split(" ")
firstnewsinfo = firstnewsinfo3[0]
press_text.append(firstnewsinfo)
firstnewstime = firstnewsinfo3[1]
time_text.append(firstnewstime)
print(firstnews + " - " + firstnewsinfo + " - " + firstnewstime)
print(firstnewshref + "\n")
result = {"time": time_text, "title": title_text, "press": press_text, "link": link_text}
df = pd.DataFrame(result) # df로 변환
outputFileName = '%s(%s.%s.%s %s시 %s분 %s초).xlsx' % (location_text, now.year, now.month, now.day, now.hour, now.minute, now.second)
df.to_excel(RESULT_PATH + outputFileName, sheet_name='sheet1')
main()crawler 함수 정의.
크롤링하는 단계는 쉽기 때문에 보고 익히면 될 듯함.
crawler이 실행되기 전 만들어져있던 배열들을 Dict에 key와 value 형식으로 저장한 후 pd.DataFrame으로 엑셀 파일에 입힐 수 있게 만들어준다.
main() 실행.
실행화면
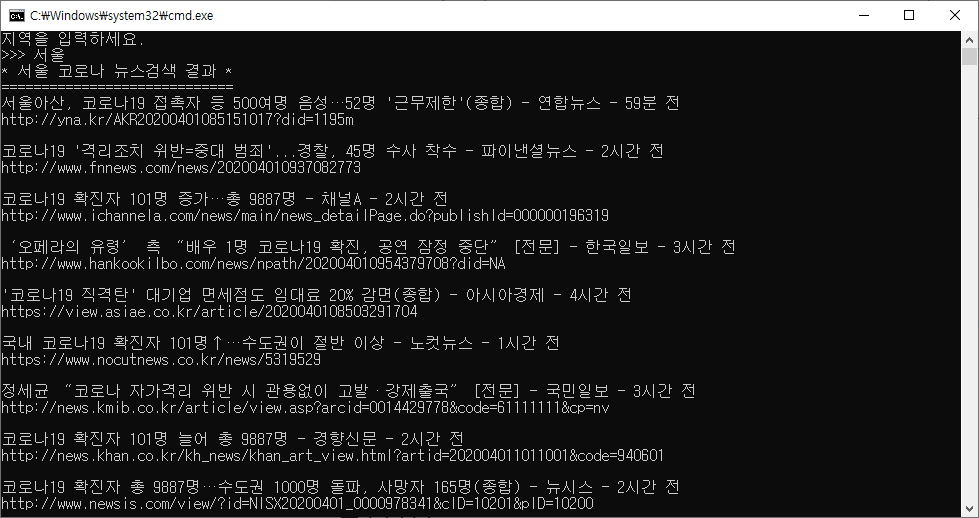
오류없이 실행한 모습.

지역 이름을 쓰지 않을 경우.
코딩 후기
가재맨 구독좀 ㅋㅋ
728x90
반응형
'Development Study > Python' 카테고리의 다른 글
| [Python] datetime 모듈에 대해서 (0) | 2020.04.03 |
|---|---|
| [Python] sys 모듈의 exit() 함수에 대해서 (0) | 2020.04.02 |
| [Python] 파이썬 웹 크롤링으로 날씨 정보를 크롤링해보자 (0) | 2019.12.26 |
| [Python] Python Pickle, 파이썬 피클 모듈 (0) | 2019.11.24 |
| [Python] isalpha(), isalnum() 함수 (0) | 2019.11.20 |
'Development Study/Python' Related Articles
more



Comments